Introduction
This webpage discusses how to run programs using GPU on maya 2013. The NVIDIA K20 is a powerful general purpose graphics processing unit (GPGPU) with 2496 computational cores which is designed for efficient double-precision calculation. GPU accelerated computing has become popular in recent years due to the GPU’s ability to achieve high performance in computationally intensive portions of code beyond a general purpose CPU. The NVIDIA K20 GPU has 5 GB of onboard memory.
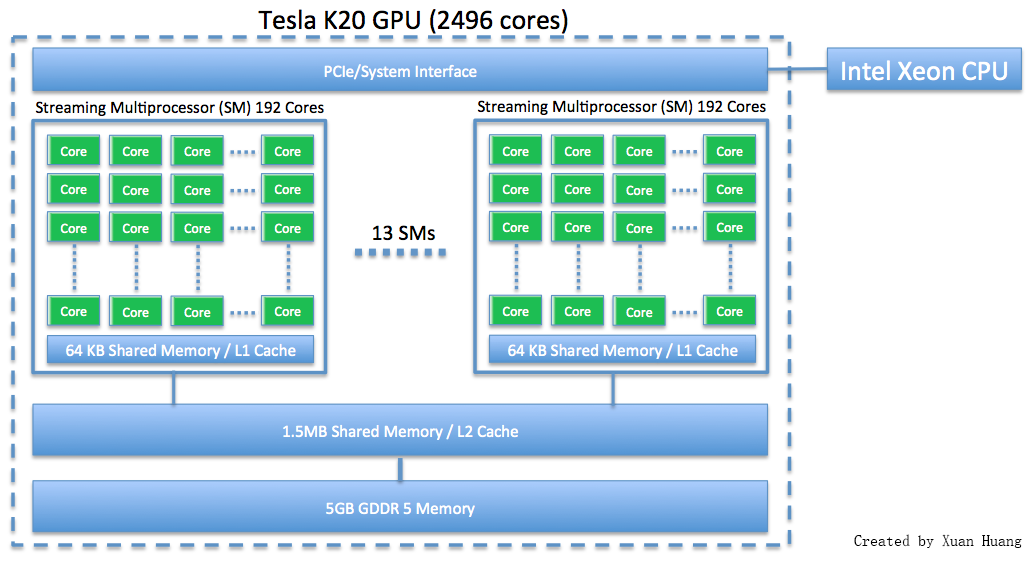 |
Before proceeding, make sure you’ve read the How To Run tutorial first. To follow along, ensure you are logged into maya-usr1 and have the CUDA modules loaded.
[hu6@maya-usr1 ~]$ module list Currently Loaded Modulefiles: 1) dot 7) intel-mpi/64/4.1.3/049 2) matlab/r2014a 8) texlive/2014 3) comsol/4.4 9) default-environment 4) gcc/4.8.2 10) cuda65/blas/6.5.14 5) slurm/14.03.6 11) cuda65/toolkit/6.5.14 6) intel/compiler/64/14.0/2013_sp1.3.174
NOTE: Our current module of GCC is not supported by CUDA 6.5 or CUDA 7.0. To remedy this, please UNLOAD the GCC module (command: module unload gcc) and use the version of GCC provided by RedHat in /usr/bin (version 4.4.7).
Example – Hello World from GPU
In CUDA programming language, CPU and the system’s memory are referred to as host, and the GPU and its memory are referred to as device. Figure below explains how threads are grouped into blocks, and blocks grouped into grids.
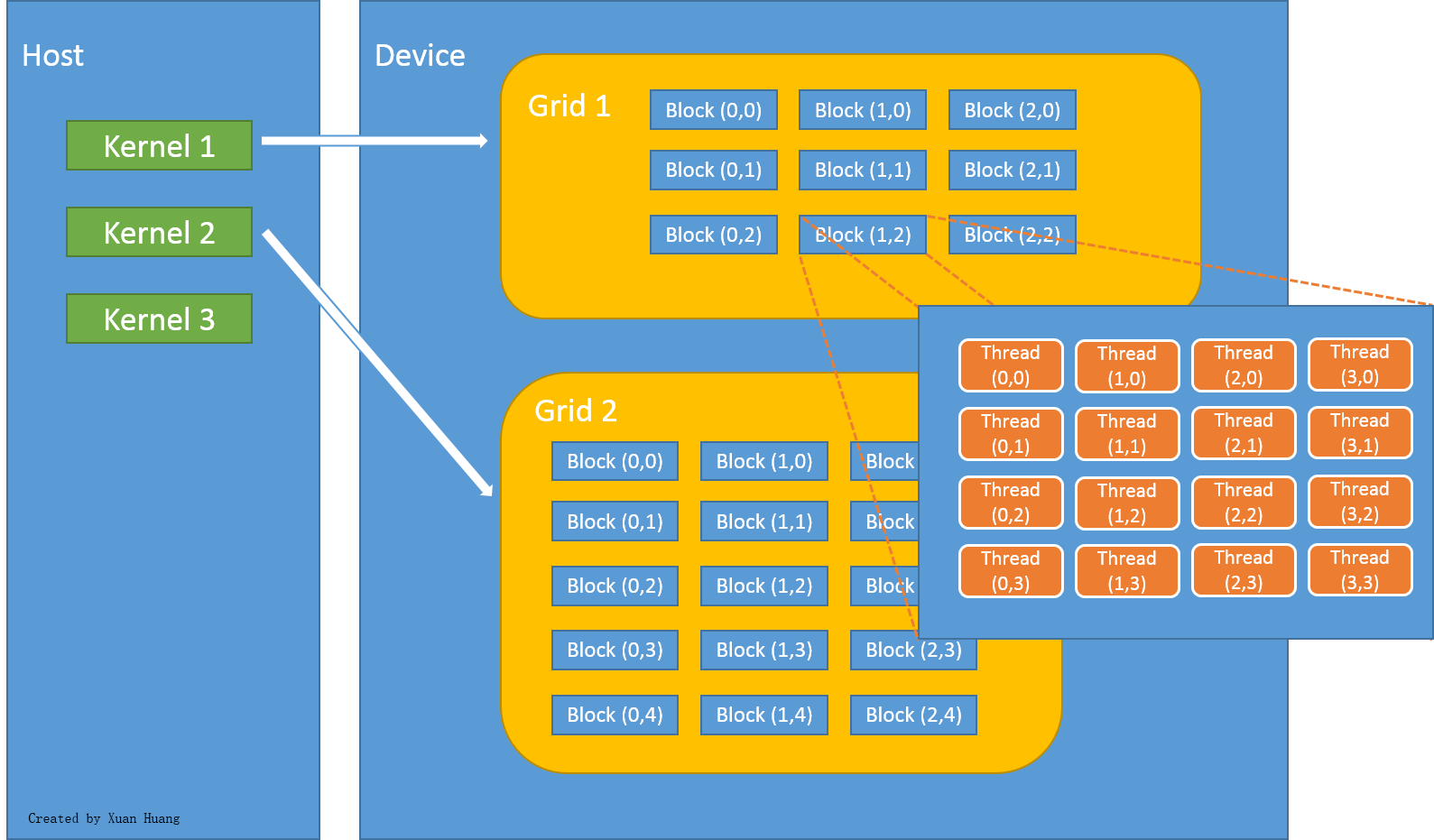 |
Threads unite into thread blocks — one- two or three-dimensional grids of threads that interact with each other via shared memory and synchpoints. A program (kernel) is executed over a grid of thread blocks. One grid is executed at a time. Each block can also be one-, two-, or three-dimensional in form. This is due to the fact that GPUs used to work on graphical data, which has 3 dimensions red, green and blue. This now gives much flexibility in launching kernels with different data structure. However, there are still limitations, such as one block can only have no more than 1024 threads, regardless of dimension.
Let’s start with a Hello World program using the GPU.
Download: ..code/hello_gpu/hello.cu
We can compile with NVIDIA’s NVCC compiler. Normally, the compiler does not allow devices to use the host function printf, however, if we compile with the flag -arch=sm_20, it can be done. The GPU that we have on maya is K20, and it supports the sm_35 architecture.
[hu6@maya-usr1 test04_hello]$ nvcc -arch=sm_35 hello.cu -o hello
We need to submit the job using the following slurm file, so it will run on a node that has GPU.
Download: ..code/hello_gpu/run.slurm
Upon executation, Host (CPU) launchs a kernel on Device (GPU) that prints Hello World and corresponding block id and thread id.
[hu6@maya-usr1 test04_hello]$ cat slurm.out Hello world! I'm thread 0 in block 0 Hello world! I'm thread 1 in block 0 Hello world! I'm thread 2 in block 0 Hello world! I'm thread 3 in block 0 Hello world! I'm thread 4 in block 0 Hello world! I'm thread 5 in block 0 Hello world! I'm thread 6 in block 0 Hello world! I'm thread 7 in block 0 Hello world! I'm thread 8 in block 0 Hello world! I'm thread 9 in block 0 Hello world! I'm thread 10 in block 0 Hello world! I'm thread 11 in block 0 Hello world! I'm thread 12 in block 0 Hello world! I'm thread 13 in block 0 Hello world! I'm thread 14 in block 0 Hello world! I'm thread 15 in block 0 Hello world! I'm thread 0 in block 1 Hello world! I'm thread 1 in block 1 Hello world! I'm thread 2 in block 1 Hello world! I'm thread 3 in block 1 Hello world! I'm thread 4 in block 1 Hello world! I'm thread 5 in block 1 Hello world! I'm thread 6 in block 1 Hello world! I'm thread 7 in block 1 Hello world! I'm thread 8 in block 1 Hello world! I'm thread 9 in block 1 Hello world! I'm thread 10 in block 1 Hello world! I'm thread 11 in block 1 Hello world! I'm thread 12 in block 1 Hello world! I'm thread 13 in block 1 Hello world! I'm thread 14 in block 1 Hello world! I'm thread 15 in block 1 That's all!
Example – Compile Host only and Device only program
Now we’ll try to run a slightly more complicated program, which has several files.
The main.cu program below will launch kernels and call function.
Download: ..code/make_gpu/main.cu
The file kernel.cu contains code that will run on GPU.
Download: ..code/make_gpu/kernel.cu
Download: ..code/make_gpu/kernel.h
The file hostOnly.cu contains code that only runs on CPU.
Download: ..code/make_gpu/hostOnly.cu
Download: ..code/make_gpu/hostOnly.h
The file Makefile is used to compile and link all CUDA files.
Download: ..code/make_gpu/Makefile
After successful compilation, we need the following slurm file to launch the job on a GPU node.
Download: ..code/make_gpu/run.slurm
The program will put the output in the file slurm.out:
Download: ..code/make_gpu/slurm.out
For more information about programming CUDA, see the NVIDIA Programming Guide website.