Table of Contents
The taki Cluster
The taki cluster is a heterogeneous cluster with equipment acquired in 2009, 2013, and 2018.
For access, taki is divided into three clusters of distinct types, with components from several dates of purchases. This structure is reflected by the tabs on top of this webpage.
- CPU Cluster: The 179 nodes total to over 3000 cores and over 20 TB pooled memory!
- HPCF2018: 42 compute and 2 develop nodes, each with two 18-core Intel Skylake CPUs and 384 GB of memory,
- HPCF2013: 49 compute, 2 develop, and 1 interactive nodes, each with two 8-core Intel Ivy Bridge CPUs and 64 GB of memory,
- HPCF2009: 82 compute and 2 develop nodes, each with two 4-core Intel Nehalem CPUs and 24 GB of memory;
- GPU Cluster:
- HPCF2018: 1 GPU node containing 4 NVIDIA Tesla V100 GPUs connected by NVLink and 2 Intel Skylake CPUs,
- HPCF2013: 18 CPU/GPU nodes, each a hybrid node with 2 CPUs and 2 NVIDIA K20 GPUs;
- Big Data Cluster:
- HPCF2018: 8 Big Data nodes, each with 2 CPUs and 48 TB disk space;
- Other Nodes:
- 2 login/user nodes (taki-usr1, taki-usr2),
- 1 management node.
See the System Description under the CPU tab for the complete description of taki, see the Big Data tab for more details about the Big Data cluster, and see the following for more details on the GPU cluster.
The GPU Cluster in taki
- HPCF2018 [gpu2018 partition]:
- 1 GPU node (
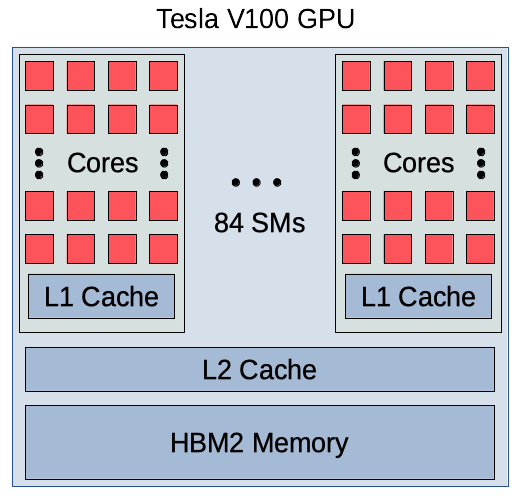
gpunode001) containing four NVIDIA Tesla V100 GPUs (5120 computational cores over 84 SMs, 16 GB onboard memory) connected by NVLink and two 18-core Intel Skylake CPUs, - The node has 384 GB of memory (12 x 32 GB DDR4 at 2666 MT/s) and a 120 GB SSD disk,
- 1 GPU node (
- HPCF2013 [gpu partition with constraint hpcf2013]:
- 18 hybrid CPU/GPU nodes (
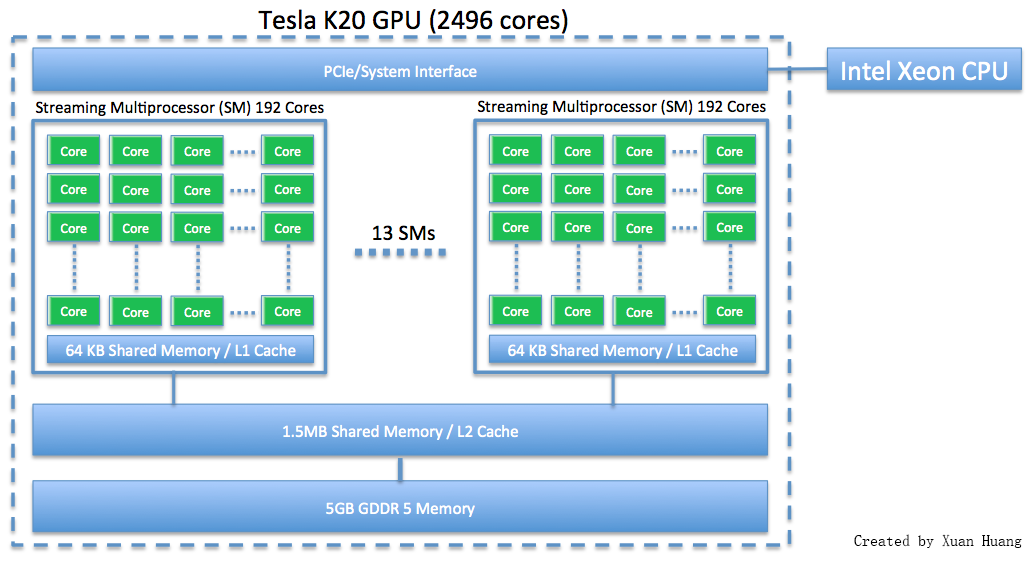
gpunode[101-118]), each two NVIDIA K20 GPUs (2496 computational cores over 13 SMs, 4 GB onboard memory) and two 8-core Intel E5-2650v2 Ivy Bridge CPUs (2.6 GHz clock speed, 20 MB L3 cache, 4 memory channels), - Each node has 64 GB of memory (8 x 8 GB DDR3) and 500 GB of local hard drive,
- The nodes are connected by a QDR (quad-data rate) InfiniBand switch;
- 18 hybrid CPU/GPU nodes (
The following schematics show the architectures of the two node types contained in the GPU cluster.
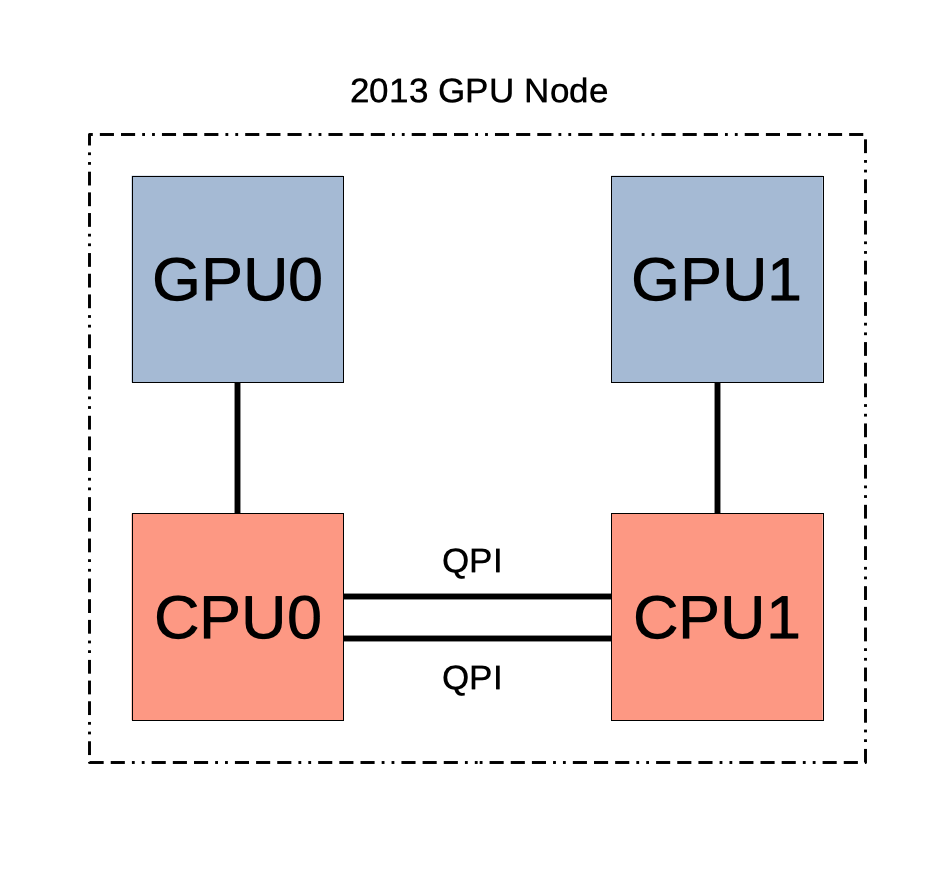
The Tesla K20, shown in the first schematic below, contains 2496 cores over 13 SMs and 5 GB of onboard memory. The second schematic shows how the GPUs are connected in the hybrid CPU/GPU node for HPCF2013. The node contains two Tesla K20 GPUs, each connected to a separate Ivy Bridge CPU. While the CPUs are connected by QPI, there is no connection between the GPUs. In order for the GPUs to communicate with each other, any shared information must pass between the CPUs. Therefore the GPUs cannot operate independently of the CPUs.
 |
 |
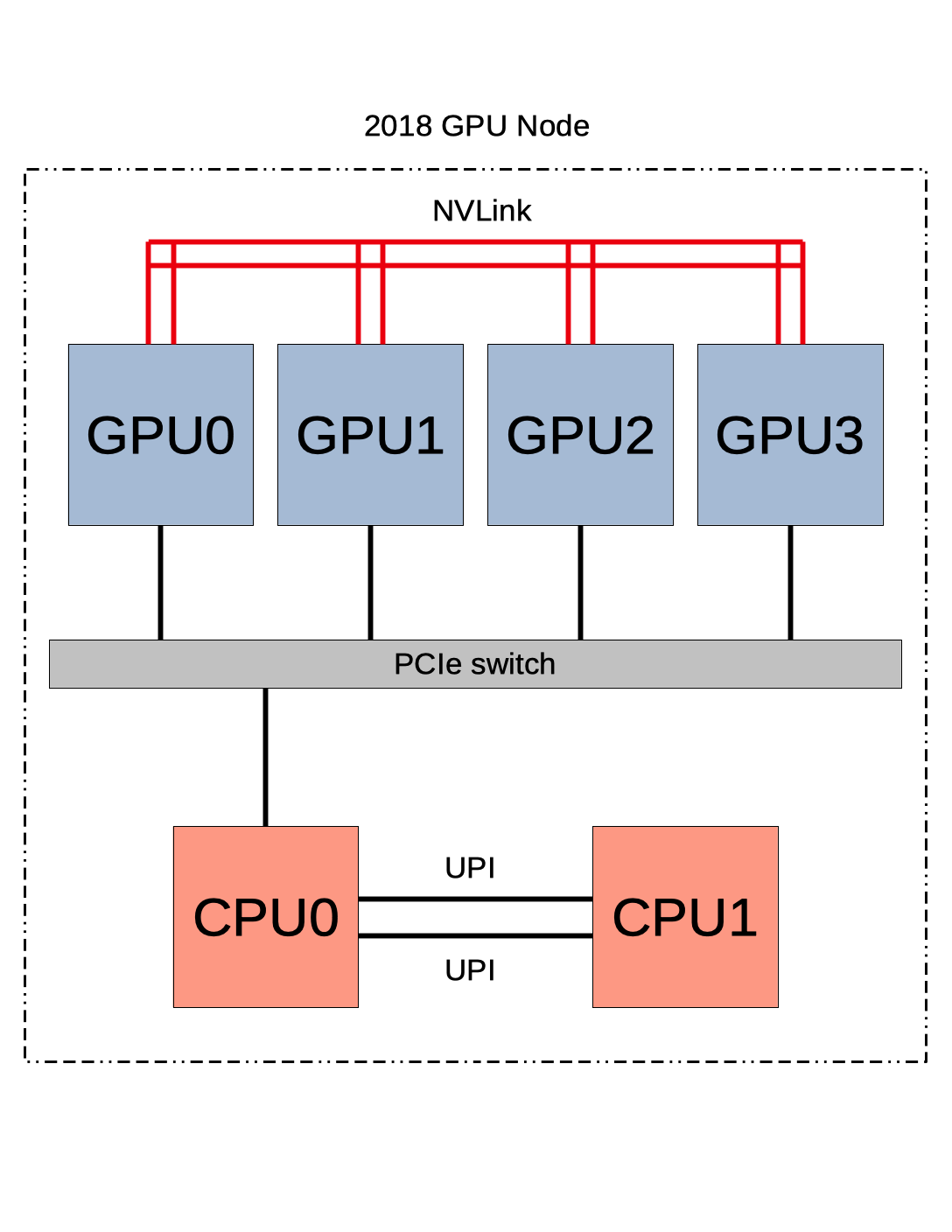
The architecture of the newer Tesla V100 GPU is shown in the first schematic below. It contains 5120 cores over 84 SMs and 16 GB of onboard memory. In addition, each V100 contains 640 tensor cores. The four Tesla V100 GPUs contained in the GPU node for HPCF2018 are arranged in the configuration shown in the second schematic. Notice that all GPUs are tightly connected through NVLink, allowing information to be shared between them without passing through the CPUs. The node contains two Skylake CPUs that are connected to each other by UPI. A PCIe switch is used to connect the GPUs to the first CPU [Han, Xu, and Dandapanthula 2017] [Xu, Han, and Ta 2019]. Given the relative richness of the connections between GPUs, jobs run on this node should primarily use the GPUs rather than the CPUs.
 |
 |
Storage
There are a few special storage systems attached to the clusters, in addition to the standard Unix filesystem. Here we describe the areas which are relevant to users.
Home directory
Each user has a home directory on the /home partition. Users can only store 300 MB of data in their home directory.
Research Storage
Users are also given space on this storage area which can be accessed from anywhere on the cluster. There is space in research storage available for user and group storage. These are accessible via symbolic links in users’ home directories. Note that this area is not backed up.
Scratch Space
All compute nodes have a local /scratch directory, and it is generally about 100 GB in size. Slurm creates a folder in this directory. Slurm sets ‘JOB_SCRATCH_DIR’ to the directory for the duration of the job. Users have access to this folder only for the duration of their job. After jobs are completed, this space is purged. This space is shared between all users, but your data is accessible only to you. This space is safer to use for jobs than the usual /tmp directory, since critical system processes also require use of /tmp.
Tmp Space
All nodes (including the user node) have a local /tmp directory and it is generally 40 GB in size. Any files in a machines /tmp directory are only visible on that machine and the system deletes them once in a while. Furthermore, the space is shared between all users. It is preferred that users make use of Scratch Space over /tmp whenever possible.
UMBC AFS Storage Access
Your AFS partition is the directory where your personal files are stored when you use the DoIT computer labs or the gl.umbc.edu login nodes. The UMBC-wide /afs can be accessed from the taki login nodes.