Table of Contents
maya cluster
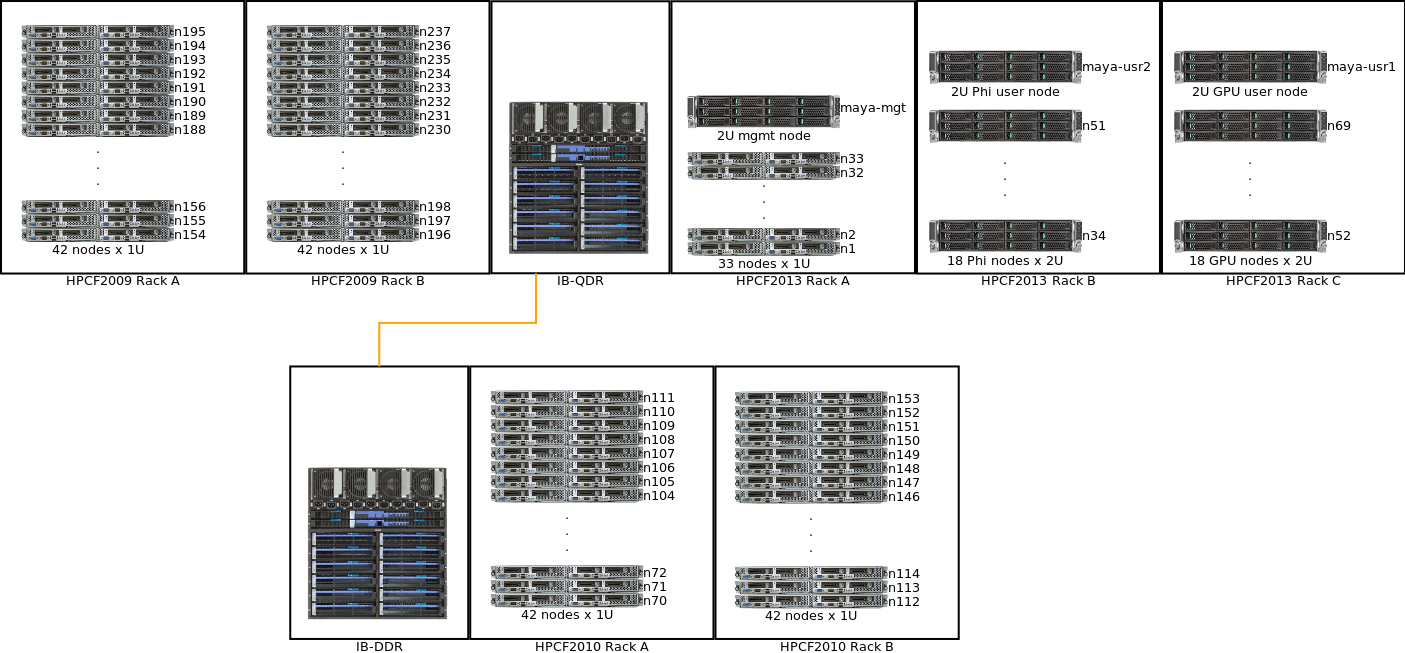
The maya cluster is a heterogeneous cluster with equipment acquired between 2009 and 2013. It contains a total of 324 nodes, 38 GPUs and 38 Intel Phi coprocessors, and over 8 TB of main memory. The name maya is from a concept in Hinduism that means “illusion”, and that the human experience comprehends only a tiny fragment of the fundamental nature of the universe. Previous cluster names tara and kali also originate from Hinduism. For more information about using your account on the system, see this page.
- HPCF2013: Dell 4220 cabinets with 34 PowerEdge R620 CPU-only compute nodes, 19 PowerEdge R720 CPU/GPU compute nodes, and 19 PowerEdge R720 CPU/Phi compute nodes. Dell nodes will be referred to collectively as HPCF2013. All nodes have two Intel E5-2650v2 Ivy Bridge (2.6 GHz, 20 MB cache), processors with eight cores apiece, for a total of 16 cores per node. CPU/GPU nodes have two NVIDIA K20 GPUs, while CPU/Phi have two Intel Phi 5110P coprocessors. All nodes have 64 GB of main memory, except those designated as user nodes which have 128 GB, and 500 GB of local hard drive.
- HPCF2010: Four IBM Server x iDataPlex cabinets with 163 compute nodes originally purchased in 2010 and later merged into HPCF. These nodes will be referred to as HPCF2010. Each node features two (2) quad core Intel Nehalem X5560 processors (2.8 GHz, 8 MB cache), 24 GB of memory, and a 230 GB local hard drive.
- HPCF2009: Two IBM Server x iDataPlex cabinets with 86 compute nodes originally purchased in 2009 by HPCF and deployed in November 2009 as the cluster tara. These nodes will be referred to as HPCF2009. Each node features two (2) quad core Intel Nehalem X5550 processors (2.6 GHz, 8 MB cache), 24 GB of memory, and a 120 GB local hard drive.
All nodes are running Red Hat Enterprise Linux 6.4.A schematic of the layout of maya is given below. The system is composed of two major networks, labeled IB-QDR and IB-DDR. For more information about these networks, see the Network Hardware section below. Notice that the HPCF2013 and HPCF2009 nodes are on the network IB-QDR, while the HPCF2010 nodes are on IB-DDR.
Some photos of the cluster are given below.
 Racks, front Racks, front |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
The Ivy Bridge and Nehalem CPUs in maya have some features which should benefit large-scale scientific computations. Each processor has its own memory channels to its dedicated local memory, which should offer efficient memory access when multiple cores are in use. The CPUs have also been designed for optimized cache access and loop performance. For more information about the CPUs, see:
- Silicon Technology from Intel
- Wikipedia: Ivy Bridge
- Wikipedia: Nehalem
- Intel Xeon E5-2650v2 (Ivy Bridge)
- Intel Xeon X5550 (Nehalem)
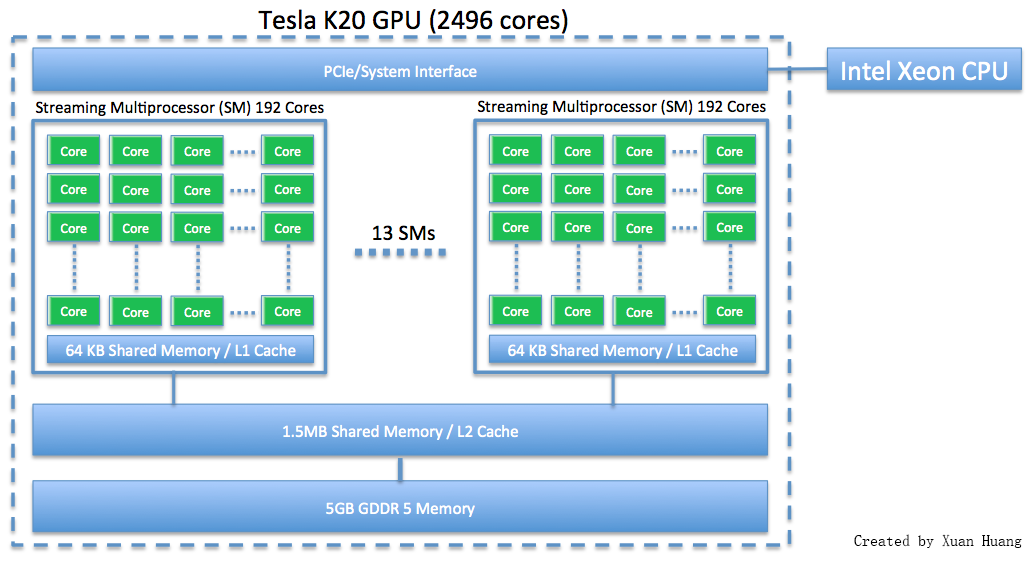
The following schematics show the architecture of the CPUs, GPUs, and Phis for the HPCF2013. First schematic shows one of the compute nodes that consists of two eight-core 2.6~GHz Intel E5-2650v2 Ivy Bridge CPUs. Each core of each CPU has dedicated 32~kB of L1 and 256~kB of L2 cache. All cores of each CPU share 20~MB of L3 cache. The 64~GB of the node’s memory is the combination of eight 8~GB DIMMs, four of which are connected to each CPU. The two CPUs of a node are connected to each other by two QPI (quick path interconnect) links. Nodes are connected by a quad-data rate InfiniBand interconnect.
The NVIDIA K20 is a powerful general purpose graphics processing unit (GPGPU) with 2496 computational cores which is designed for efficient double-precision calculation. GPU accelerated computing has become popular in recent years due to the GPU’s ability to achieve high performance in computationally intensive portions of code beyond a general purpose CPU. The NVIDIA K20 GPU has 5 GB of onboard memory.
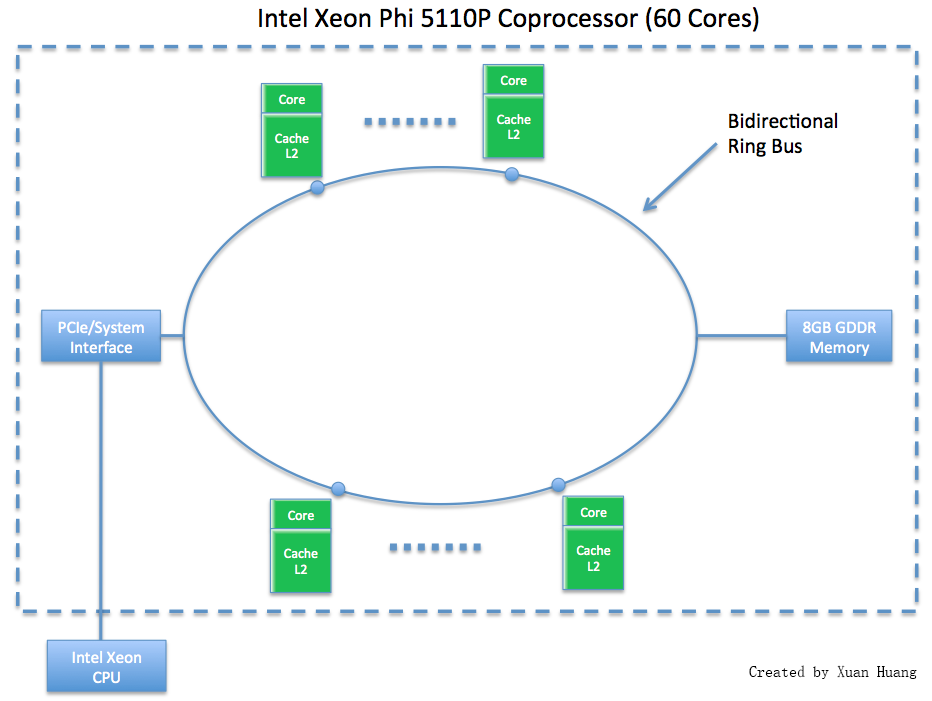
The Intel Phi 5110P is a recent offering from Intel, which packages 60 cores into a single coprocessor. Each core is x86 compatible and is capable of running its own instruction stream. The x86 compatibility allows the programmer to use familiar frameworks such as MPI and OpenMP when developing code for the Phi. The Phi 5110P has 8 GB of onboard memory.
 |
 |
 |
Some HPCF technical reports contain performance studies that show how to use the cluster in a profitable way (i.e. good performance using the latest equipment):
- HPCF-2012-11 studies the performance of the HPCF2009 racks on a large data problem – traversal of massive distributed graphs. This is done in the context of the Graph500 benchmark. In this work, it is seen that using all eight cores on each node leads to a degraded performance.
The maya cluster contains several types of nodes that fall into four main categories for usage.
- Management node – There is one management node, which is reserved for administration of the cluster. It is not available to users.
- User nodes – Users work on these nodes directly. This is where users log in, access files, write and compile code, and submit jobs to the scheduler from to be run on the compute nodes. Furthermore, these are the only nodes that may be accessed via SSH/SCP from outside of the cluster. Because maya is a heterogeneous cluster, several user nodes are available; both reside in the HPCF2013 portion of the cluster:
- maya-usr1 – user node which includes two GPUs for GPU code development.
- maya-usr2 – user node which includes two Phi coprocessors for Phi code development.
- Compute nodes – These nodes are where the majority of computing on the cluster will take place. Users normally do not interact with these nodes directly. Instead jobs are created and submitted from the user nodes and a program called the scheduler decides which compute resources are available to run the job.In principle a user could connect to compute nodes directly from a user node by SSH (e.g. “ssh n84”). However, SSH access to the compute nodes is disabled to help maintain stability of the cluster. Compute nodes should instead be allocated by the scheduler. Advanced users should be very careful when doing things such as spawning child processes or threads – you must ensure that you are only using the resources allocated to you by the scheduler. It is best to contact HPCF user support if there are questions about how to set up a non-standard job on maya.
- Development nodes – These are special compute nodes which are dedicated to running code that is under development. This allows users to test their programs and not interfere with programs running in production. Programs are also limited to a short maximum run time on these nodes to make sure users don’t need to wait too long before a program will run. Development jobs are expected to be small in scale, but rerun frequently as you work on your code.The availability of two development nodes allows you to try several useful configurations: single core, several cores on one processor, several cores on multiple processors of one machine, all cores on multiple machines, etc. Currently, there are two (2) HPCF2009, two (2) HPCF2010, and two (2) HPCF2013 CPU-only node which are reserved for development.
The maya cluster features several different computing environments. We ask that, when there is no specific need to use the Dell equipment, users should use the HPCF2010 nodes first. Then the HPCF2009 nodes. The HPCF2013 CPU-only nodes should be used when HPCF2009 is filled, and the GPU and Phi-enabled nodes should only be used when all other nodes are unavailable. The scheduler will be set up to help enforce this automatically.
The table below gives the hostnames of all nodes in the cluster, and to which hardware group and cabinet they belong.
| Hardware Group | Rack | Hostnames | Description |
|---|---|---|---|
| hpcf2013 | A | maya-mgt | Management node, for admin use only |
| A | n1, n2, …, n33 | CPU-only compute nodes. n1 and n2 are currently designated as development nodes |
|
| B | maya-usr2 | User node with Phis | |
| B | n34, n35, …, n51 | Compute nodes with Phis | |
| C | maya-usr1 | User node with GPUs | |
| C | n52, n53, …, n69 | Compute nodes witth GPUs | |
| hpcf2010 | A | n70, n71, …, n111 | Compute nodes n70 and n71 are currently designated as a development node |
| B | n112, n113, …, n153 | Compute nodes | |
| C | n238, n239, …, n279 | Compute nodes | |
| D | n280, n281, …, n321 | Compute nodes n302-n321 are currently designated as hadoop nodes |
|
| hpcf2009 | A | n154, n155, …, n195 | Compute nodes n154 and n155 are currently designated as a development node |
| B | n196, 198, …, n237 | Compute nodes | |
Network Hardware
Two networks connect all components of the system:
- For communications among the processes of a parallel job, a high performance InfiniBand interconnect with low latency and wide bandwidth connects all nodes as well as connects to the central storage. This amounts to having a parallel file system available during computations.
- A quad data rate (QDR) Infiniband switch connects the HPCF2009 and HPCF2013 cabinets. Ideally the system can achieve a latency of 1.2usec to transfer a message between two nodes, and can support a bandwidth of up to 40 Gbps (40 gigabits per second). We refer to this switch as IB-QDR.
- A double data rate (DDR) Infiniband switch connects the HPCF2010 cabinets. We refer to this switch as IB-DDR.
- Nodes on IB-QDR can communicate with those on IB-DDR through an Infiniband connection. But note that this comes at the price of decreased performance, therefore users are advised to design jobs that avoid high bandwidth communications between switches.
- A conventional Ethernet network connects all nodes and is used for operating system and other connections from the user node to the compute nodes that do not require high performance. It also connects the long-term storage (see below) to the cluster.
For more information about the network components, see:
Storage
There are a few special storage systems attached to the clusters, in addition to the standard Unix filesystem. Here we descibe the areas which are relevant to users. See Using Your Account for more information about how to access the space.
- Home directory – Each user has a home directory on the /home partition. This partition is 200 GB and its data is backed up by DoIT. Since the partition is fairly small, users can only store 100 MB of data in their home directory.
- Scratch Space – All compute nodes have a local /scratch directory and it is generally about 100 GB in size. Files in /scratch exist only for the duration of the job that created them. This space is shared between all users, but your data is accessible only to you. This space is safer to use for jobs than the usual /tmp directory, since critical system processes also require use of /tmp
- Tmp Space – All nodes (including the user node) have a local /tmp directory and it is generally 40 GB in size. Any files in a machines /tmp directory are only visible on that machine and the system deletes them once in a while. Furthermore, the space is shared between all users. It is preferred that users make use of Scratch Space over /tmp whenever possible.
- Central Storage – Users are also given space on this storage area which can be accessed from anywhere on the cluster. Spaces in central storage area are available for personal workspace as well as group workspace.
- UMBC AFS Storage on maya – Your AFS partition is the directory where your personal files are stored when you use the DoIT computer labs or the gl.umbc.edu login nodes. The UMBC-wide /afs can be accessed from maya.