THIS PAGE EXISTS AS A HISTORIC REFERENCE. The Intel Phi on Maya from 2013 were first-generation x100 KNC co-processor cards. We stopped supporting them on Maya, in particular since the second-generation x200 KNL stand-alone CPUs became available in 2016.
Introduction
This webpage discusses how to run programs in the Intel Xeon Phi.
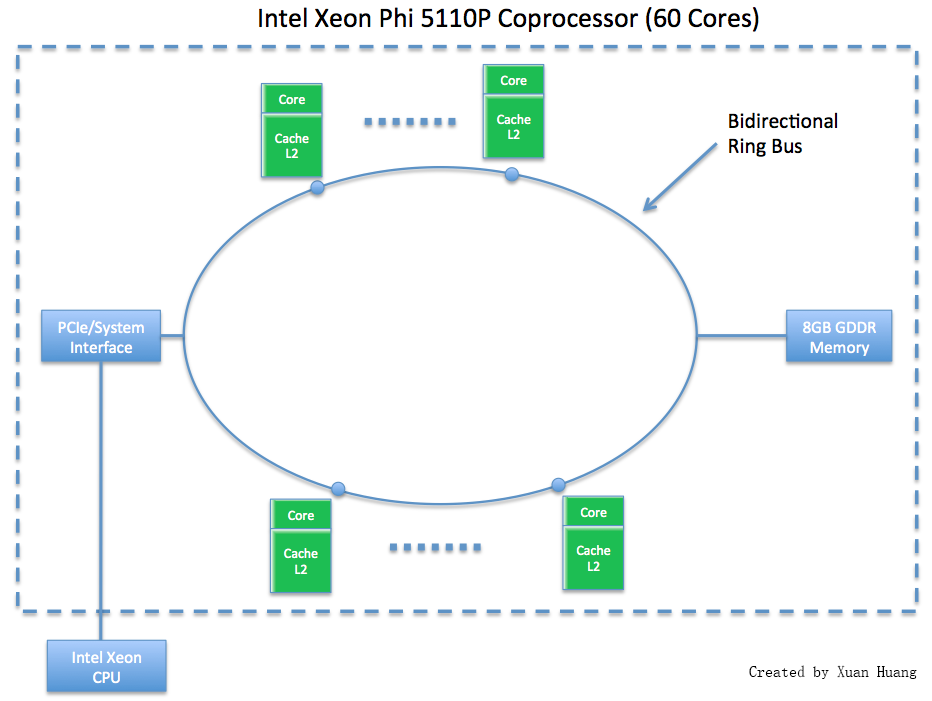 |
An Intel Phi packages 60 cores into a single coprocessor. The cores are connected to each other and main memory through a bidirectional ring bus. Each core is x86 compatible and is capable of running its own instruction stream. The x86 compatibility allows the programmer to use familiar frameworks such as MPI and OpenMP when developing code on the Phi. The Phi 5110P, which is on maya, has 8 GB of onboard memory. There are three main modes of running programs on the Intel Phi:
- Native Mode, where the program is run directly on the Phi. In this mode it is possible to have serial jobs and parallel jobs using MPI and/or OpenMP.
- Offload Mode, where the program is run on the CPU and segments of the code are moved (or offloaded) to the Phi.
- Symmetric mode, where the program is run both on the CPU and directly on the Phi concurrently.
To follow along, ensure you are logged into maya-usr2 and have the Intel MPI and MIC modules loaded.
This webpage is based on slides provided by Colfax International during a Developer Boot Camp on July 15, 2014 sponsored by Intel. For more information about programming on the Phi, see the Intel Developer Zone website.
NOTE: All Intel Phi code should be run from your home space, the Intel Phi does NOT have access to group storage.
Native Mode on Phi
When compiling on native mode you must load the module intel-mpi/mic and unload the module intel-mpi/64 so that you have the following modules loaded.
[khsa1@maya-usr2 hello_phi]$ module list Currently Loaded Modulefiles: 1) dot 8) intel/mic/runtime/3.3 2) matlab/r2014a 9) default-environment 3) comsol/4.4 10) intel-mpi/mic/4.1.3/049 4) gcc/4.8.2 11) intel/compiler/64/15.0/full 5) slurm/14.03.6 6) texlive/2014 7) intel/mic/sdk/3.3
Example: Serial Code
Let’s try to compile this simple Hello World program:
Download: ..code/hello_phi/hello_native.c
We can compile with the Intel compiler with the -mmic flag so that the compiler knows that this code will be run natively on the Phi.
[khsa1@maya-usr2 hello_phi]$ icc hello_native.c -o hello_native -mmic
We submit the job using the following slurm script so that it will run on a Phi.
Download: ..code/hello_phi/run-native.slurm
Upon execution, the job will be allocated a Phi and then be executed.
[khsa1@maya-usr2 hello_phi]$ cat slurm.out Hello world! I have 240 logical cores.
Since this is a serial job that only uses one core of the sixty available on the Phi it is possible to run several of these jobs on one core at the same time.
Example: Code with OpenMP
Now we will look at how to run a program with OpenMP natively on the Phi. We will compile the following Hello World program:
Download: ..code/hello_phi/hello_openmp.c
We can compile with the Intel compiler and Intel MPI with the -mmic flag so that the compiler knows that this code will be run natively on the Phi. We also use the -openmp flag so that the compiler knows that this code will use OpenMP.
[khsa1@maya-usr2 hello_phi]$ icc -mmic -openmp -o hello_openmp hello_openmp.c
After compilation, we run the following slurm script to run the job on a Phi node.
Download: ..code/hello_phi/run-openmp.slurm
The program will put the output in the file slurm.out:
[khsa1@maya-usr2 hello_phi]$ cat slurm.out Hello from thread 000 of 008 Hello from thread 001 of 008 Hello from thread 002 of 008 Hello from thread 003 of 008 Hello from thread 004 of 008 Hello from thread 005 of 008 Hello from thread 006 of 008 Hello from thread 007 of 008
Example: Code with MPI
Now we will look at how to run a program which uses MPI natively on the Phi. We will compile the following Hello World program:
Download: ..code/hello_phi/hello_mpi.c
We can compile with the Intel compiler and Intel MPI with the -mmic flag so that the compiler knows that this code will be run natively on the Phi.
[khsa1@maya-usr2 hello_phi]$ mpiicc -mmic -o hello_mpi hello_mpi.c
After compilation, we run the following slurm script to run the job on a Phi node.
Download: ..code/hello_phi/run-mpi.slurm
The program will put the following output in the file slurm.out:
[khsa1@maya-usr2 hello_phi]$ cat slurm.out Hello world from process 001 out of 008, processor name n51-mic0 Hello world from process 002 out of 008, processor name n51-mic0 Hello world from process 003 out of 008, processor name n51-mic0 Hello world from process 005 out of 008, processor name n51-mic0 Hello world from process 006 out of 008, processor name n51-mic0 Hello world from process 000 out of 008, processor name n51-mic0 Hello world from process 004 out of 008, processor name n51-mic0 Hello world from process 007 out of 008, processor name n51-mic0
Example: Code with MPI and OpenMP
Now we will look at how to run a program which uses MPI and OpenMP natively on the Phi. We will compile the following Hello World program in the file ‘hello_openmp_mpi.c’:
#include <stdio.h>
#include <mpi.h>
#include <omp.h>
int main (int argc, char *argv[])
{
int id, np;
char processor_name[MPI_MAX_PROCESSOR_NAME];
int processor_name_len;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &np);
MPI_Comm_rank(MPI_COMM_WORLD, &id);
MPI_Get_processor_name(processor_name, &processor_name_len);
#pragma omp parallel
{
printf("Hello world from thread %03d out of %03d on process %03d out of %03d, processor name %s\n",
omp_get_thread_num(), omp_get_num_threads(), id, np, processor_name );
}
MPI_Finalize();
return 0;
}
We can compile with the Intel compiler and Intel MPI with the -mmic flag so that the compiler knows that this code will be run natively on the Phi, and the -openmp flag to include OpenMP libraries.
[slet1@maya-usr2 hello_phi]$ mpiicc -mmic -openmp -o hello_openmp_mpi hello_openmp_mpi.c
After compilation, we run the following slurm script to run the job on a Phi node.
#!/bin/bash #SBATCH --job-name=hello_phi #SBATCH --output=slurm.out #SBATCH --error=slurm.err #SBATCH --partition=mic #SBATCH --exclusive #SBATCH --nodes=1 #SBATCH --ntasks-per-node=1 unset I_MPI_FABRICS export DAPL_DBG_TYPE=0 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/cm/shared/apps/intel/composer_xe/current/compiler/lib/mic export OMP_NUM_THREADS=2 mpiexec.hydra -n 2 ./hello_openmp_mpi
The program will put the following output in the file slurm.out:
Hello world from thread 000 out of 002 on process 000 out of 002, processor name n34-mic1 Hello world from thread 001 out of 002 on process 000 out of 002, processor name n34-mic1 Hello world from thread 000 out of 002 on process 001 out of 002, processor name n34-mic1 Hello world from thread 001 out of 002 on process 001 out of 002, processor name n34-mic1
Native Mode on Multiple Phis
Now we will run a program which uses native mode on multiple Phis. We use the code with both MPI and OpenMP as an example. In order to allow for communication between multiple Phis, the following lines must be added to the ~/.ssh/config file.
Host *
StrictHostKeyChecking no
UserKnownHostsFile=/dev/null
We will compile the following Hello World program in the file ‘hello_openmp_mpi.c’:
#include <stdio.h>
#include <mpi.h>
#include <omp.h>
int main (int argc, char *argv[])
{
int id, np;
char processor_name[MPI_MAX_PROCESSOR_NAME];
int processor_name_len;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &np);
MPI_Comm_rank(MPI_COMM_WORLD, &id);
MPI_Get_processor_name(processor_name, &processor_name_len);
#pragma omp parallel
{
printf("Hello world from thread %03d out of %03d on process %03d out of %03d, processor name %s\n",
omp_get_thread_num(), omp_get_num_threads(), id, np, processor_name );
}
MPI_Finalize();
return 0;
}
We can compile with the Intel compiler and Intel MPI with the -mmic flag so that the compiler knows that this code will be run natively on Phis, and the -openmp flag to include OpenMP libraries.
[khsa1@maya-usr2 hello_phi]$ mpiicc -mmic -openmp -o hello_openmp_mpi hello_openmp_mpi.c
After compilation, we run the following slurm script to run the job on 2 Phis.
#!/bin/bash #SBATCH --job-name=hello_phi #SBATCH --output=slurm.out #SBATCH --error=slurm.err #SBATCH --partition=mic #SBATCH --exclusive #SBATCH --nodes=4 #SBATCH --ntasks-per-node=1 unset I_MPI_FABRICS export DAPL_DBG_TYPE=0 export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/cm/shared/apps/intel/composer_xe/current/compiler/lib/mic export OMP_NUM_THREADS=2 export I_MPI_JOB_RESPECT_PROCESS_PLACEMENT=OFF mpiexec.hydra -n 8 -perhost 2 ./hello_openmp_mpi
The program will put the following output in the file slurm.out:
Hello world from thread 000 out of 002 on process 000 out of 008, processor name n34-mic0 Hello world from thread 001 out of 002 on process 000 out of 008, processor name n34-mic0 Hello world from thread 000 out of 002 on process 001 out of 008, processor name n34-mic0 Hello world from thread 001 out of 002 on process 001 out of 008, processor name n34-mic0 Hello world from thread 000 out of 002 on process 002 out of 008, processor name n34-mic1 Hello world from thread 001 out of 002 on process 002 out of 008, processor name n34-mic1 Hello world from thread 000 out of 002 on process 003 out of 008, processor name n34-mic1 Hello world from thread 001 out of 002 on process 003 out of 008, processor name n34-mic1 Hello world from thread 000 out of 002 on process 004 out of 008, processor name n40-mic0 Hello world from thread 001 out of 002 on process 004 out of 008, processor name n40-mic0 Hello world from thread 000 out of 002 on process 005 out of 008, processor name n40-mic0 Hello world from thread 001 out of 002 on process 005 out of 008, processor name n40-mic0 Hello world from thread 000 out of 002 on process 006 out of 008, processor name n40-mic1 Hello world from thread 001 out of 002 on process 006 out of 008, processor name n40-mic1 Hello world from thread 000 out of 002 on process 007 out of 008, processor name n40-mic1 Hello world from thread 001 out of 002 on process 007 out of 008, processor name n40-mic1
This may produce the following output in the error file:
Warning: Permanently added 'n34-mic1,10.1.34.2' (ECDSA) to the list of known hosts. Warning: Permanently added 'n40-mic0,10.1.40.1' (ECDSA) to the list of known hosts. Warning: Permanently added 'n40-mic1,10.1.40.2' (ECDSA) to the list of known hosts.
Offload Mode on the Phi
When compiling in offload mode the default-environment module may be loaded.
[khsa1@maya-usr2 hello_phi]$ module list Currently Loaded Modulefiles: 1) dot 9) intel/mic/sdk/3.3 2) matlab/r2014a 10) intel/mic/runtime/3.3 3) comsol/4.4 11) default-environment 4) gcc/4.8.2 5) slurm/14.03.6 6) intel/compiler/64/14.0/2013_sp1.3.174 7) intel-mpi/64/4.1.3/049 8) texlive/2014
Now we will run programs which uses offloading to run part of the code on the CPU and part of the code on the Phi.
Example: Offload Mode with a Single Phi
The program below will first print a message from the CPU. It will then offload to the Phi, print a message, and return to the CPU. The code inside of the #pragma offload is offloaded to the Phi. Note that if offloading fails then the code will be run entirely on the CPU. We check if the the offloading was successful by checking if __MIC__ is defined.
Download: ..code/hello_phi/hello_offload.c
Since this code is not run natively on the Phi we do not need to add the -mmic flag.
[khsa1@maya-usr2 hello_phi]$ icc hello_offload.c -o hello_offload
After compilation, we run the following slurm script to run the job on a Phi node.
Download: ..code/hello_phi/run-offload.slurm
The program will put the output in the file slurm.out:
[khsa1@maya-usr2 hello_phi]$ cat slurm.out Hello World from CPU! Hello World from Phi!
Example: Offload Mode with Multiple Phis
Now we will run a program which uses offloading to run part of the code on the CPU and part of the code on the two Phis connected to the node.
This program uses MPI on the CPU and OpenMP on the Phi. Since by default processes are distributed in a round-robin fashion the two CPUs with the 0-th process being on the CPU 0, if we let the even ranks offload to mic0 and the odd ranks offload to mic1 we will can split the work between the two Phis. To do this, we specify the micid in the offload pragma statement.
Download: ..code/hello_phi/hello_multioffload.c
Since this code uses MPI we must use mpiicc to compile and add the -openmp flag since we use OpenMP on the Phis.
[khsa1@maya-usr2 hello_phi]$ mpiicc -openmp hello_multioffload.c -o hello_multioffload
After compilation, we run the following slurm script to run the job on a Phi node.
Download: ..code/hello_phi/run-multioffload.slurm
The program will put the output in the file slurm.out:
[khsa1@maya-usr2 hello_phi]$ cat slurm.out Hello World from rank 0 on n34! Hello World from rank 1 on n34! Hello World from rank 1 on n34-mic1 Hello World from rank 0 on n34-mic0
Example: Offload Mode with Data Transfer and Offloading Functions
In this example we will demonstrate how to write and compile a more advanced example of code with offloading to the Phi. In this example we will show how to transfer data onto the Phi and how to create functions that are used only on the Phi.
The code we will look at performs an axpby operation on the Phi and transfers the resulting vector back to the CPU. Before we look at the code it is important to note that scope-local scalars and known-size arrays are offloaded automatically, however dynamically allocated data must be explicitly transferred between the CPU and Phi.
The file main.c demonstrates two methods to perform this computation on the Phi. In the first method we add the inout command to the offload pragma statment. This command should contain all variables that are used inside of the offload region that are not already automatically offloaded, i.e. all dynamically allocated variables. In our case this would be the vectors x, y, and z1. The variables are then followed by a colon and the command length(n), where n is the length of the vectors. This command will transfer the data to the Phi, call the function axpby1 on the Phi, and transfer the vectors x, y, and z1 along with any data that was offloaded automatically back to the CPU.
The second method is to first transfer all data to the Phi, then call a function which contains the offload regions inside of it that will perform the operation, and finally transfer the resulting vectors back to the CPU. To first transfer the data to the Phi we use the in command in the offload pragma. Just as before, we transfer in the x, y, and z2 arrays that were dynamically allocated and specify the length of these vectors. However, now we add ALLOC after the colon. As we can see on the first line of main.c, the ALLOC macro allocates these vectors on the Phi but does not free them upon exiting the offload region. The function axpby2, which is defined in axpby.c, is called on the CPU but the resulting vector z2 remains on the Phi. So, we use another offload pragma with the out command to transfer the z2 vector back to the CPU. This out command uses the FREE macro after the colon so that the associated memory is freed on the Phi. Since we will no longer need the Phi but the vectors x and y are still on the Phi, the nocopy command is used for the vectors x and y and the memory associated with these vectors is also freed. This method is useful if you have a function that must be called several times and requires operations on both the CPU and the Phi, allowing you to avoid unnecessary communications between the CPU and Phi as in the first method.
Download: ..code/phi/main.c
Now we will look at the axpby.c and axpby.h files. Since the function axpby1 is used only on the Phi it must be marked with the specifier __attribute__((target(mic))). This means that it can only be called from an offload region. The function axpby2 does not contain this specifier so it cannot be called from an offload region. If this function needs to perform an operation on the Phi it must use an offload region. Since we already offloaded z, x, and y to the Phi we can reuse these vectors in an offload region inside the function. We use the in command in the offload pragma but instead of providing the real length of these vectors we simply provide a length of 0 and use the REUSE macro so that there are no transfers between the CPU and Phi.
Download: ..code/phi/axpby.c
Download: ..code/phi/axpby.h
The file Makefile is used to compile and link all files.
Download: ..code/phi/Makefile
We run the following slurm script to run the job on a Phi node. Note that we add the line export OFFLOAD_REPORT=2, causing offload details to be printed to standard output. This is useful for debugging to determine how much time is used on transferring data between the Phi and CPU. Note that the value of the OFFLOAD_REPORT environment variable can be set as 0, 1, 2, or 3 for varying levels of verbosity.
Download: ..code/phi/run.slurm
The program will result in the following output in the slurm.out file. As we can see both methods result in the correct output. By looking at the output of the offload report, we observe that the second method requires the transfer of less data and less time in the offload regions.
[khsa1@maya-usr2 phi]$ cat slurm.out x[0]=0.000000 x[1]=1.000000 x[2]=2.000000 x[3]=3.000000 x[4]=4.000000 x[5]=5.000000 x[6]=6.000000 x[7]=7.000000 y[0]=1.000000 y[1]=2.000000 y[2]=3.000000 y[3]=4.000000 y[4]=5.000000 y[5]=6.000000 y[6]=7.000000 y[7]=8.000000 [Offload] [MIC 0] [File] main.c [Offload] [MIC 0] [Line] 32 [Offload] [MIC 0] [Tag] Tag 0 [Offload] [HOST] [Tag 0] [CPU Time] 0.796314(seconds) [Offload] [MIC 0] [Tag 0] [CPU->MIC Data] 212 (bytes) [Offload] [MIC 0] [Tag 0] [MIC Time] 0.248634(seconds) [Offload] [MIC 0] [Tag 0] [MIC->CPU Data] 192 (bytes) [Offload] [MIC 0] [File] main.c [Offload] [MIC 0] [Line] 37 [Offload] [MIC 0] [Tag] Tag 1 [Offload] [HOST] [Tag 1] [CPU Time] 0.004586(seconds) [Offload] [MIC 0] [Tag 1] [CPU->MIC Data] 192 (bytes) [Offload] [MIC 0] [Tag 1] [MIC Time] 0.000066(seconds) [Offload] [MIC 0] [Tag 1] [MIC->CPU Data] 24 (bytes) [Offload] [MIC 0] [File] axpby.c [Offload] [MIC 0] [Line] 14 [Offload] [MIC 0] [Tag] Tag 2 [Offload] [HOST] [Tag 2] [CPU Time] 0.000511(seconds) [Offload] [MIC 0] [Tag 2] [CPU->MIC Data] 44 (bytes) [Offload] [MIC 0] [Tag 2] [MIC Time] 0.000334(seconds) [Offload] [MIC 0] [Tag 2] [MIC->CPU Data] 20 (bytes) [Offload] [MIC 0] [File] main.c [Offload] [MIC 0] [Line] 42 [Offload] [MIC 0] [Tag] Tag 3 [Offload] [HOST] [Tag 3] [CPU Time] 0.011541(seconds) [Offload] [MIC 0] [Tag 3] [CPU->MIC Data] 48 (bytes) [Offload] [MIC 0] [Tag 3] [MIC Time] 0.000060(seconds) [Offload] [MIC 0] [Tag 3] [MIC->CPU Data] 64 (bytes) z1[0] = 1.000000 z1[1] = 4.000000 z1[2] = 7.000000 z1[3] = 10.000000 z1[4] = 13.000000 z1[5] = 16.000000 z1[6] = 19.000000 z1[7] = 22.000000 z2[0] = 1.000000 z2[1] = 4.000000 z2[2] = 7.000000 z2[3] = 10.000000 z2[4] = 13.000000 z2[5] = 16.000000 z2[6] = 19.000000 z2[7] = 22.000000
Example: Symmetric Mode with CPU and Phi
Finally, we will explain how to code in symmetric mode. In this mode we have one MPI world accross both CPUs and Phis working concurrently. In the following example we will have 8 MPI processes on the CPU and 8 MPI Processes on the Phi.
We will again use hello_mpi.c but it will now be run on the a CPU and Phi:
Download: ..code/hello_phi/hello_mpi.c
Since this code will be run on both a CPU and a Phi two executables need to be compiled:
[khsa1@maya-usr2 hello_phi]$ mpiicc -mmic hello_mpi.c -o hello_mpi.MIC [khsa1@maya-usr2 hello_phi]$ mpiicc hello_mpi.c -o hello_mpi.XEON
The hello_mpi.XEON executable is compiled to be run on the CPU and the hello_mpi.MIC is compiled to be run on the Phi.
Download: ..code/hello_phi/run-symmetric.slurm
This program will result in the following output in the slurm.out file:
[khsa1@maya-usr2 hello_phi]$ cat slurm.out Hello world from process 008 out of 016, processor name n34 Hello world from process 009 out of 016, processor name n34 Hello world from process 010 out of 016, processor name n34 Hello world from process 011 out of 016, processor name n34 Hello world from process 012 out of 016, processor name n34 Hello world from process 013 out of 016, processor name n34 Hello world from process 014 out of 016, processor name n34 Hello world from process 015 out of 016, processor name n34 Hello world from process 000 out of 016, processor name n34-mic0 Hello world from process 001 out of 016, processor name n34-mic0 Hello world from process 002 out of 016, processor name n34-mic0 Hello world from process 003 out of 016, processor name n34-mic0 Hello world from process 004 out of 016, processor name n34-mic0 Hello world from process 005 out of 016, processor name n34-mic0 Hello world from process 006 out of 016, processor name n34-mic0 Hello world from process 007 out of 016, processor name n34-mic0